Introduction
“(The) First Rule in government spending: Why build one when you can have two at twice the price?” - S.R. Hadden in Contact, 1997 (written by Carl Sagan).
S.R. Hadden, the wealthy industrialist in the Carl Sagan drama Contact, may have been poking fun at stereotypical government spending practices when he quipped the line above, but his statement was more profound than it sounds, and it is especially relevant to clinical laboratory test utilization. The health care payment systems operating today in many countries remove the clinicians who make utilization decisions from the financial consequences of their actions, with the result that some patients undergo at least twice the testing at twice the price, if not much more.
That test overutilization exists is no longer an item of debate, and it is clearly an international problem (1). The reasons for overutilization are myriad, and may include as enabling factors even the technology we use to perform laboratory testing. There was once a time when it would be unthinkable and impractical for a hospital inpatient to get multiple laboratory tests per day, every day (2), but in the present day, high frequency testing is almost the rule in resource-rich settings, rather than the exception. Instrument vendors now advertise turnaround times in minutes rather than hours or days for clinical assays, automated platforms handle hundreds to thousands of samples per hour, and data systems distribute the results of these tests electronically, directly to caregiver’s electronic inboxes. In the outpatient care setting, testing may not occur daily for each patient, but the barrier to getting testing can be incredibly low; the standard routine “physical” that a healthy adult might receive at a doctor visit can be accompanied by a panel of tests, perhaps only a blood count and electrolytes, but possibly also any one of a myriad of large so-called “wellness” panels offered by commercial laboratories that have financial incentives to drive frequent, high-cost testing. It does not simplify matters that additional technological advances, especially the genomic revolution, have exponentially increased the number of possible tests that are available. No one clinician can possibly know which novel test is appropriate in any given situation, and the problem compounds itself daily as additional genetic tests, small molecule mass spectrometry tests, or proteomic multivariate index assays are added to the global test menu. Absent any guidance, it appears that clinicians are apt to order whatever seems most familiar, any or all tests that sound like they might be appropriate, or whatever has been touted most heavily by ambitious sales representatives. Another problem unique to academic settings is that one must allow for the fact that physicians in training may need to order more than an optimal number of tests in order to learn how to use the results of this testing in the practice of medicine.
So, what is a laboratory director to do in the face of this growing adversity? How do we ensure that that patient’s interests come first, that neither inpatients nor outpatients get the wrong tests at all or the right tests too frequently, and that caregivers are able to select tests appropriately so that they can most easily interpret the results? Laboratory test utilization researchers, including this author, have often summed up the literature in lectures or in private by stating that, “30% of laboratory testing is likely wasteful,” and now this estimate has been supported by a thorough meta-analysis (3). However, it is has never been clear exactly how laboratory directors or clinicians should go about identifying those 30% of tests, especially given that the wasted testing is not evenly distributed across all patients or specific tests. What is needed, therefore, is a standardized approach for identifying malutilisation in daily clinical practice, and once it has been identified, a common set of tools should be available to fix the problem. This is the approach taken in this review.
The problem of identifying inappropriate laboratory test utilization is outlined below in the form of three “Rules,” all of which are intended to provide the general rationale and goals of a laboratory test utilization management program. Afterwards, the laboratory test utilization management toolbox, comprised of a collection of evidence-based tools available to the laboratorian and clinician alike, will be described, with emphasis on those tools that are most appropriate for specific types of inappropriate utilization.
The three rules of laboratory test utilization
Rule 1: “If you ask a stupid question, you get a stupid answer”
Rule 1, otherwise known to the statistician as Bayes’ Theorem, posits that the post-test probability of something being true is a product of the prior probability that the thing is true and the likelihood ratio provided by a test (4). In mathematical terms for laboratory testing, Bayes’ Theorem can be expressed as:
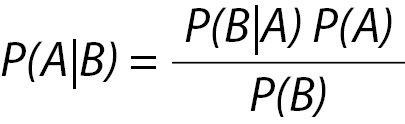
This can be translated to the context of laboratory medicine to mean that the conditional probability of disease (A) given the result of a test (B) (also called the “positive predictive value”) is equal to the conditional probability of the result (B) given the disease (A) being present, multiplied by the probability of the disease (A) in the population (also called the “prevalence”) and divided by the probability of the test giving the result (B) in all members of the population.
One consequence of Rule 1 in laboratory testing is that ordering a test to rule in a condition when the prior probability is very low (i.e. a urine hCG test to assess pregnancy in an apparently male patient) is unlikely to be a fruitful endeavor, since negative results were already expected and positive results are most likely false positives. The same applies in the converse; one should not generally order a test when it is extremely likely that the diagnosis in question is present. Rule 1 exists not just to discourage inappropriate ordering, but for the equally important reason of saving one from the onus of interpreting highly unlikely test results. The true power of testing in the setting of low pre-test probability is ruling OUT a diagnosis; negative results in these settings can be trusted, but positive results will always be confusing.
Rule 1 is not always easy to apply, however, for three reasons. One, prior probabilities of disease close to 0 or 1 or quite unusual, as clinical, radiologic, and historical findings do not always have enough evidentiary value to allow one to cease a workup without laboratory testing. The prior probability of disease could also be completely unknown, in which case the Rule helps not at all. Two, many physicians are not always able to estimate prior probabilities with enough savvy to allow an accurate application of the Rule. Clinical decision support and education can partly address this issue, but patients are all unique, so there can be no absolute guide to prior probability assessment for all situations. Three, human beings are curious, especially those who go into medicine. Curiosity manifests itself in the medical setting by exploration of unlikely possibilities, and while this may be an important educational activity, it should not be the basis for sound medical policy.
The three challenges of Rule 1 notwithstanding, the Rule can still be followed effectively by 1) using Bayesian thinking to assign at least relative, rather than absolute, likelihoods to various diagnoses to allow one to order sequential testing from most to least beneficial; 2) ceasing repetitive daily testing, or at least restricting testing to reflect our understanding of intraindividual biological variation, because asking “too many questions” has the same effect as asking a single “stupid question”; and 3) always developing a plan for test interpretation PRIOR to ordering a test. This third point cannot be stressed enough, especially during medical training, and even more critically in dealing with the most curious among us. Clinicians often construct large differential diagnoses in medicine to avoid missing the occasional rare presentation or to avoid anchoring bias, or perhaps simply to impress or intimidate their peers (5), but we should emphasize to our trainees that testing for many things simultaneously just because it’s possible or because “…I saw a patient like that once”, is no reason to embark upon an unnecessarily costly diagnostic odyssey. Tests ordered out of pure curiosity have a funny way of presenting later as unexplainable positive results, and the cost of working up a false positive result is always larger than not ordering the test in the first place.
Rule 2: “Laboratory testing is for sick people”
If Rule 2 sounds like a restatement of Rule 1, that is because it is. Indeed, all of laboratory test utilization management stems from Bayes’ theorem, although different restatements of the theorem provide windows into distinct aspects of the utilization management problem. What Rule 2 focuses on is the well patient, and specifically, the notion of “Wellness Testing” (6,7). Wellness Testing commonly refers to single tests or panels of tests that are intended to be performed on well patients, usually self-selecting adults, with the goal of preventing unwanted later complications of disease. Put in this way, Wellness Testing is in fact a misnomer, in that the purpose of it is to discover that a patient is, or will become, unwell. In Bayesian terms, Wellness Testing poses a significant risk of diagnostic failure, or at least confusion, in the setting of low prior probabilities. In financial terms, however, Wellness Testing creates a highly attractive market for laboratory vendors that earn money on a fee for service basis.
Like all rules, however, Rule 2 has exceptions. Lipid testing, diabetes screening and newborn screening, for example, are reasonable uses of laboratory testing in ostensibly healthy people, or at least people with prior probabilities of disease that are equivalent to the general population risk. Like many exceptions, these exceptions prove the rule. For lipid testing, one might argue that the standard “healthy” patient in a population, for example a middle-aged male who is slightly overweight and exercises a tad too little, could reasonably be considered “sick” in terms of the risk that lipid-related disorders pose to his long-term health. More importantly, however, the reason why lipid testing and newborn screening are exceptions to Rule 2 is that there exists evidence demonstrating a benefit of the testing, when coupled with appropriate downstream therapeutic interventions. In a lipid panel, we test for analytes (cholesterol, lipoproteins, triglycerides) that we know to be causally related to cardiovascular disease and that we know respond to therapy, and we understand much of the risk-benefit relationship of either measuring or not measuring lipids (8). Likewise, despite the fact that inborn errors of metabolism are exceedingly rare, and the fact that the positive results from many newborn screening tests are false positives, the testing allows us an opportunity to confirm true positives and initiate therapy to avert diseases with extremely high morbidity and mortality that would otherwise be devastatingly difficult and expensive to treat later in life. Numerous studies now indicate that newborn screening is cost-effective, as well (9-13). The WHO criteria for mass screening are a helpful resource for assessing the utility of any screening proposal (14).
The limits to Rule 2 have exceptions. Lipid testing is helpful when limited to those analytes that have been studied in large cohorts like the Framingham study (15). Newer expanded lipid panels, such as those including genetic testing (16,17), additional information about the size or chromatographic mobility of lipoprotein particles (18,19), or additional biochemical or proteomic biomarkers, run afoul of both Rule 1 and Rule 2. In some cases, these tests rely on evidence that is preliminary, limited, proprietary or otherwise insufficient to support widespread utilization, and in other cases these tests may in fact eventually find a place in appropriate lipid panels, but are currently waiting for evidence that shows us where to apply them most effectively. In the case of newborn screening, the calculus as to whether to include a test in a panel is actually fairly simple, as a test must be paired with a treatment that prevents either a disease or the squeal of that disease. If there is nothing to do with the result of a newborn screening test, then it does not make sense to do the test. That this truism extends to all laboratory testing should be obvious.
Rule 3: “Too many good tests are the same as one bad test”
Although this idea has been hinted at in Rules 1 and 2, a separate rule should be reserved for the idea that repetitive tests or large panels of tests, even when comprised by individually reasonable tests, are a form of malutilisation. At the very least, too-frequent repetitive testing can come at odds with the Nyquist-Shannon theorem, a fundamental principle of information theory (20). The mathematical derivation of the Nyquist-Shannon theorem is beyond this discussion, but in words it can be said to define the appropriate relationship between how often one should sample a varying signal. In Figure 1, 4 potential situations are depicted, in which the same oscillating laboratory value (the “signal”) is measured at successively longer intervals (the “sampling”). Clearly, plots A and B indicate oversampling, where far more laboratory tests were obtained relative to what was needed to define the underlying signal, and plot D shows significant undersampling, leading to a misleading impression that the value is oscillating slower than it is in reality. Plot C, on the other hand, has precisely as many sampling points as is necessary to describe accurately the underlying signal. In clinical terms, the Nyquist-Shannon theorem tells us that repeated testing to assess a change in a laboratory parameter should occur at intervals on par with the expected time it would take the analyte value to change.
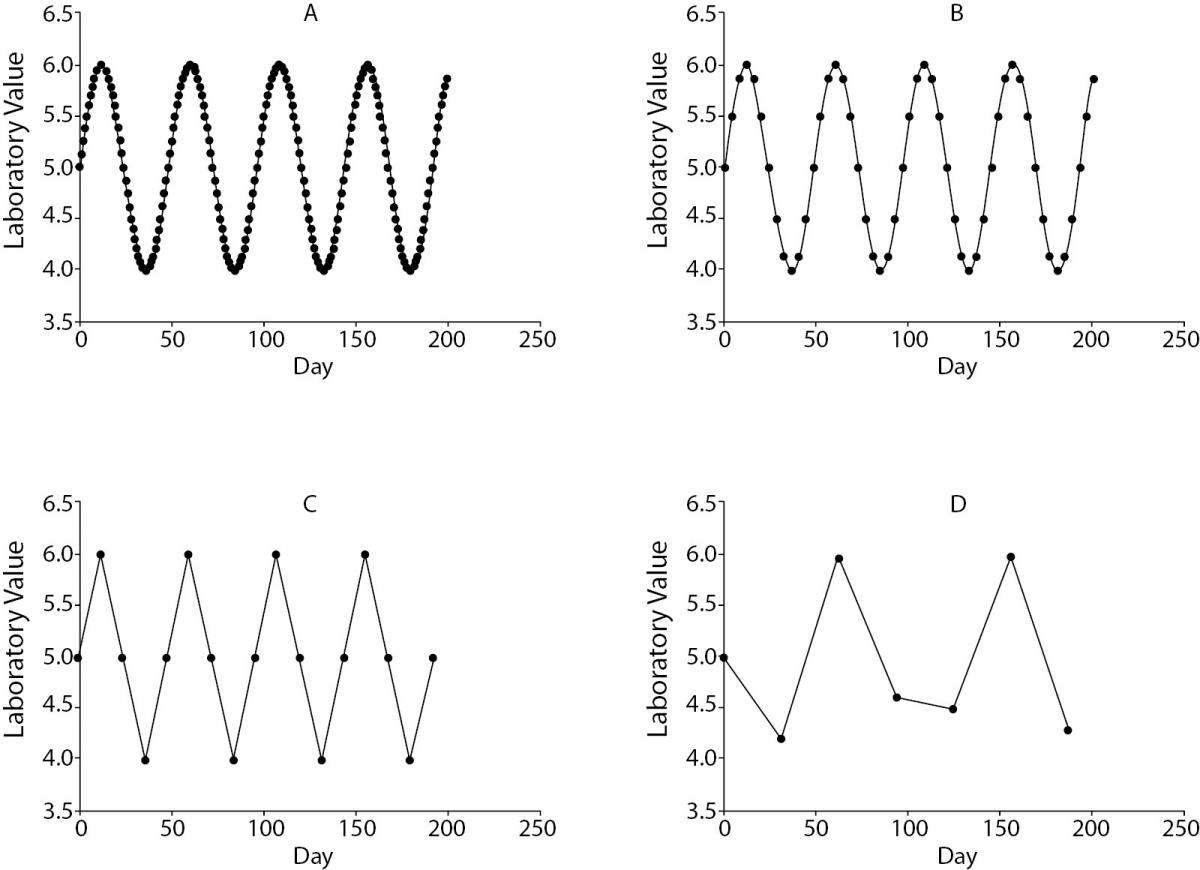
Figure 1. A hypothetical oscillating laboratory value (signal) with a period of approximately 48 days is measured once every 1 (A), 4 (B), 12 (C) and 31 (D) days.
One obvious clinical manifestation of Nyquist-Shannon theorem in clinical laboratory is in Haemoglobin A1c (HbA1c) testing. Because the longevity of red blood cells allows haemoglobin molecules to remain in circulation for several months, it makes no sense to assess HbA1c on a scale of days to weeks, but rather it should be measured on a scale of 1-3 months to assess changes. Despite the inherent logic of this conclusion, there is still substantial variation amongst physicians in ordering HbA1c testing at rational intervals (21). It is also important to understand that undersampling is a significant risk for HbA1c testing, as too-infrequent tests (i.e. a year or years between determinations in a poorly-controlled diabetic) can cause a physician to miss clinically significant variation.
A second problem with too-frequent testing derives from the statistics of repetitive applications of a single test. While the sensitivity for disease detection increases when testing repetitively, the specificity must concomitantly decrease. It is often pointed out, for example, that the chances of having one abnormal value in a panel or series of 14 tests whose reference ranges are defined by the central 95% percentile of the health population approaches 50%, even when the patient in question is totally normal (7). This counterintuitive result is of course not entirely accurate, as it assumes that all laboratory tests vary independently (they do not), but it drives home the point that the more testing is done, the more disease is discovered. This is not always a bad thing, though, and repetitive testing placed at appropriate intervals (i.e. for lipid testing) can be highly beneficial to populations. However, a disreputable laboratory vendor could also exploit this phenomenon to generate revenue from a very large panel of putative biomarker assays guaranteed to generate false positives that require follow-up testing. The phenomenon creeps even into highly complex and expensive genetic testing panels performed at reputable laboratories. For example, there are numerous genetic syndromes that are known to be each caused by a number of different possible mutations, and reference laboratories will often offer a panel of tests that probes many or all possible mutations, causative or otherwise. In such cases, it is often the case that one specific mutation is causative in the majority of cases, such that testing for a single mutation first with a cheaper screening methodology may obviate the need for the expensive full panel in a majority of patients, lowering the overall cost of testing (22). Reflexive testing algorithms that allow the providing laboratory to aid the clinician in defining the optimal sequential testing pathway are a key tool in the test utilization toolbox, and will be covered later.
Evidence that repetitive or daily testing is common abounds in the historical literature (23-31), yet fewer studies have shown how repetitive testing can drive unnecessary and costly downstream activities. In a pair of large academic medical centres, for example, daily ionized calcium testing had become ingrained into the culture of the house staff and was ordered in nearly every patient. When daily ionized calcium testing was reduced by approximately 70% by introducing a reflexive testing strategy, doses of calcium administered by the pharmacy in the hospitals decreased by a very similar fraction, as did the diagnoses of “hypocalcemia” rendered by the providers (32). While not enumerated in the report, it is likely that the cost savings of these downstream effects far outstripped the laboratory-specific savings. No discernible difference in morbidity or mortality was discovered after this intervention, even amongst diagnoses known to be associated with significant hypocalcemia (tetany, seizures, myocardial infarction). In this case, a substantial burden of disease (“hypocalcemia”) was being invented by daily ionized calcium testing practices, and it disappeared within a month as testing practices were altered, raising the question of how many other fictitious diagnoses and unnecessary treatments inpatients may receive when they undergo daily routine laboratory testing.
In another study that drew upon a large dataset comprising 4 million common outpatient tests performed in a large Canadian province (33), van Walraven et al. found that approximately 30% of testing for eight common analytes was repeated within a month. Potentially redundant testing, defined as testing repeated within defined time intervals, was estimated to have cost between $13.9 and $35.9 million (Canadian) annually. As this study only focused on 8 common tests with low unit costs, it is likely that the true cost of all redundant testing to large health care systems is probably much larger, and perhaps even orders of magnitude larger than what was observed in this study.
Guidelines have been recently published describing the “Minimum retesting interval”, i.e. the minimum time before a test should be repeated(34). While this guideline is not comprehensive of all laboratory tests and all clinical situations, it provides a substantial, evidence-based list of recommendations that covers much of the current practice of medicine.
Applying the rules
Applying the 3 rules of laboratory test utilization is a deceptively simple task, as identifying waste appears simple. However, the number of people who have decried the third of laboratory testing that is waste likely far outstrips the number of people who have ever successfully managed laboratory test utilization. Laboratory test malutilisation is thus like the weather, in that “…everyone talks about it, but no one does anything about it”. How can this be changed?
First, in an institution desiring to curb inappropriate test utilization, there must be “buy-in” amongst the key stakeholders. There must be at least one member of the laboratory staff, a laboratory director, who is willing and able to expend the time needed to do the data analyses required to identify the problem areas. If this laboratory director is in academia, as often occurs, their efforts in managing utilization should be both pursued and rewarded as genuine scholarly activities, with all work resulting in publications that allow others to learn from their successes and failures. If an academic department values contributions to test utilization management below contributions to basic or applied sciences, then junior faculty with an interest in the field will simply not participate for fear of missing out on promotion, and the field will stagnate. Outside of laboratory staff, however, cooperative medical staff are needed in the remainder of the hospital, especially those who are willing and able to take the time and energy required to participate in utilization review and quality improvement activities. Second, as utilization management is a data-intensive activity, there must be adequate information technology resources available to the project leader. At a minimum, programmers and/or individuals savvy in building, managing and querying large databases are absolutely required to generate reports and analyses, or at the very least retrieve the raw data required to assess utilization. The ability to correlate laboratory test utilization data (orders) with test results and other patient data (metadata such as gender and age, or potentially diagnostic or outcome-related data) is key for assessing the opportunities and potential risks of utilization management interventions, meaning that large relational healthcare information databases(35), although expensive, will be very valuable in future utilization studies.
The laboratory test utilization management toolbox
The laboratory test utilization management toolbox is outlined in Table 1, with interventions that drive appropriate utilization sorted from strongest to weakest. For each tool, the intended target of the tool is listed, along with potential strengths and weaknesses, and finally a reference or example of how the tool can be used. The reference column is not intended to be an exhaustive list of all published examples of a particular tool being put to use, for there are too many to include in this table, but rather the cited example(s) are intended to demonstrate an important strength or weakness of the tool.
Table 1. The laboratory test utilization management toolbox.
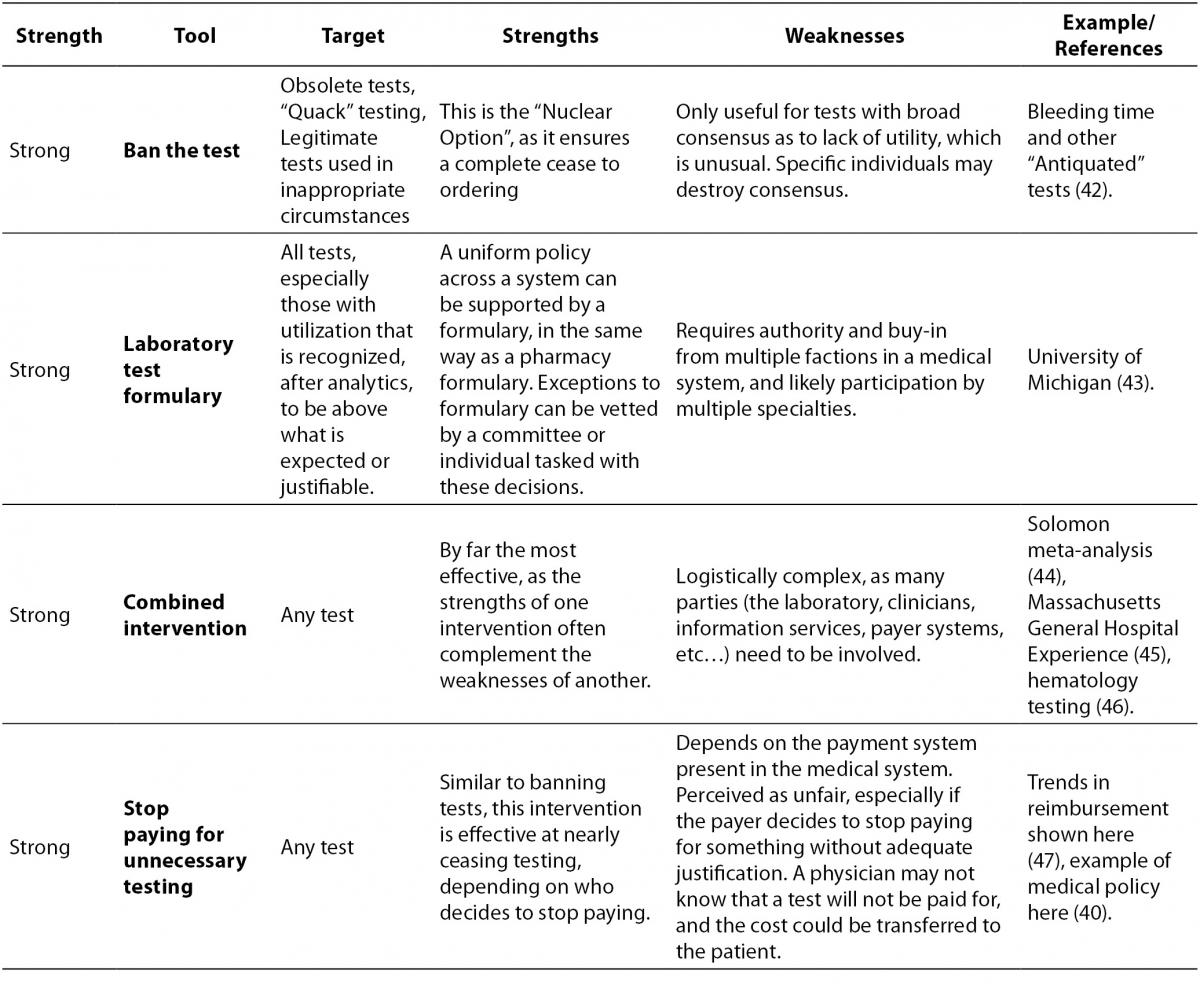
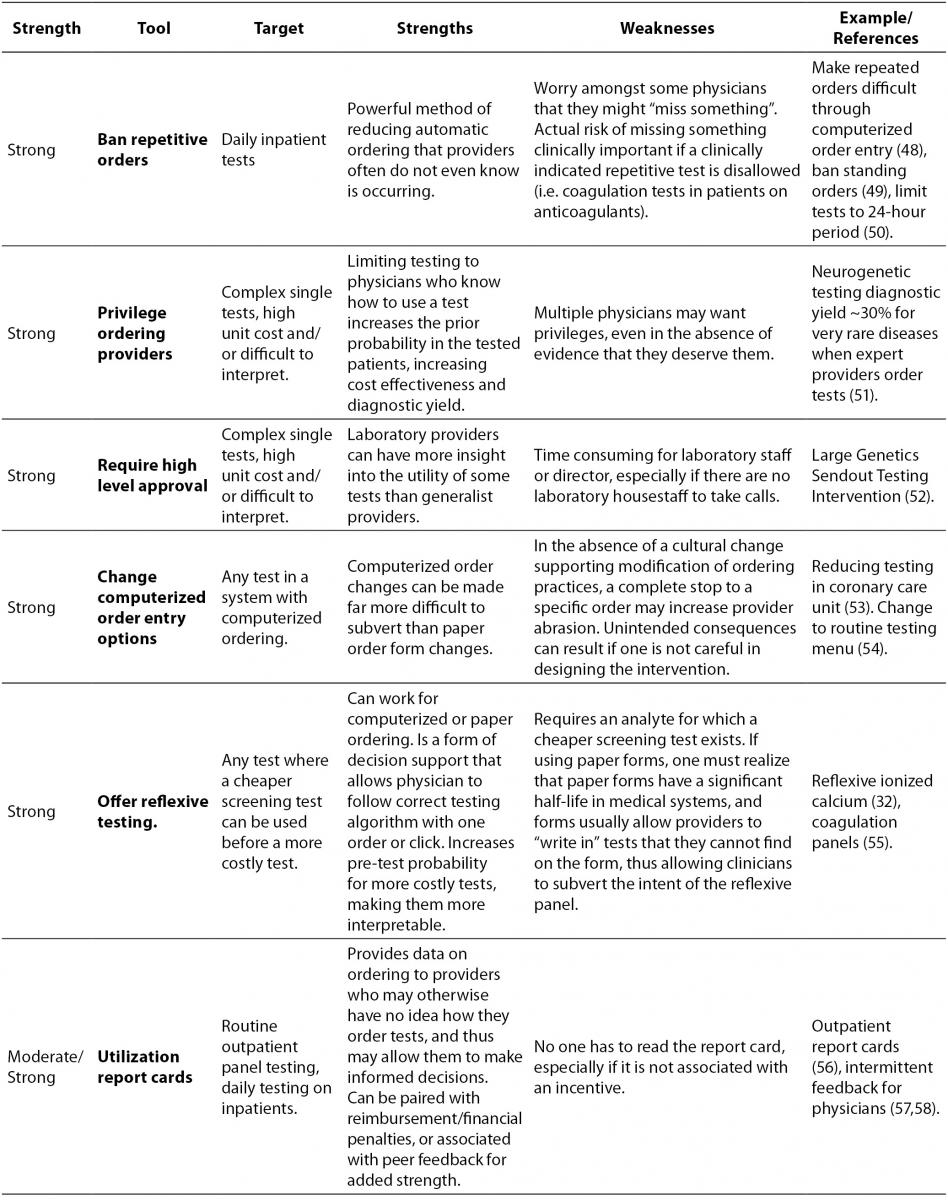
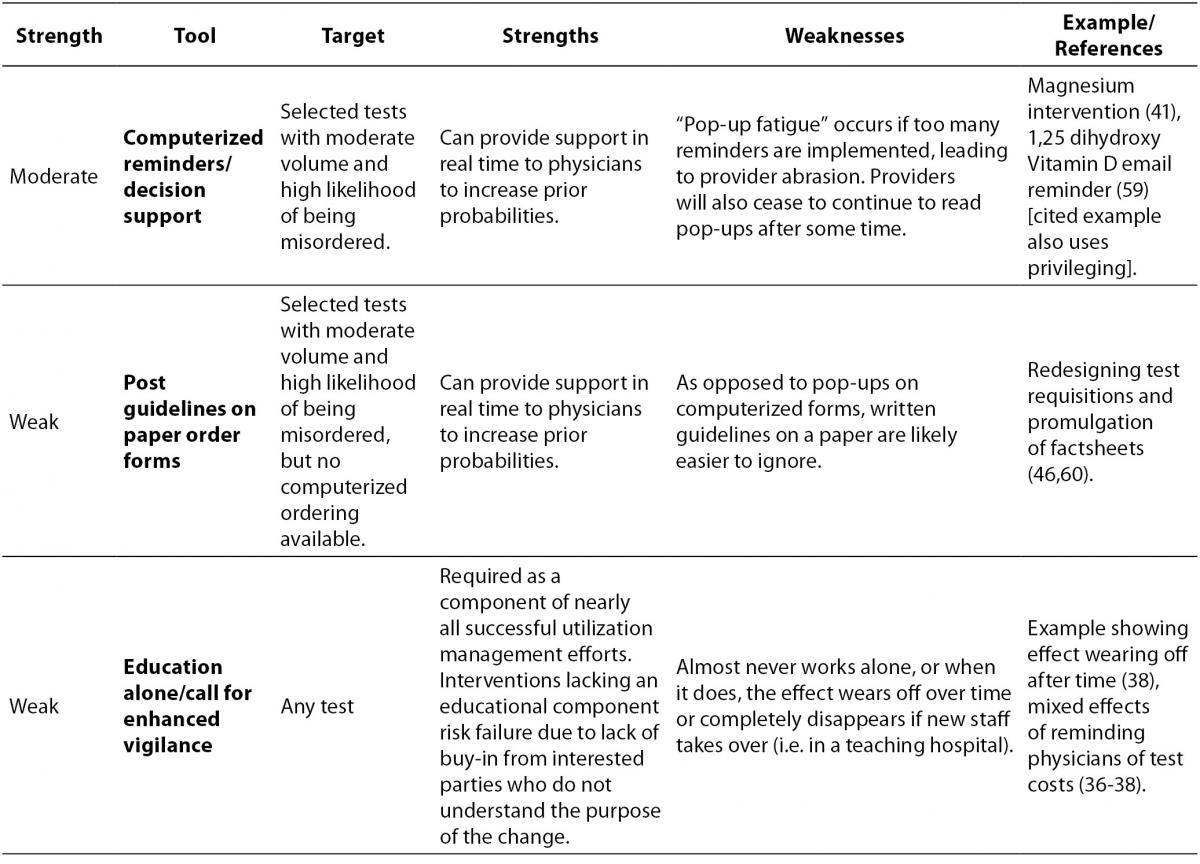
It is worth pointing out some tools that are not included in the toolbox because the available evidence suggests that they are not terribly effective. One of the common assumptions made about test utilization management is that clinicians would behave more rationally if they saw the cost of the laboratory tests they ordered. The results of interventions that actually did this are mixed (36-38), however, and do not support whether or not provision of cost information has any true effect on ordering. While it does make sense that some information about cost might influence physician ordering behavior, the potential for a successful intervention based on this information is confounded by the fact that the true costs of laboratory tests are actually quite small, compared to more expensive items like radiologic scans, and perhaps more frustrating, it is often very difficult to determine what the actual cost of a laboratory test is in some health care delivery systems. In the United States, for example, specific laboratory tests are not usually reimbursed by third party payers for inpatient stays (adults with rare diseases and some children are notable exceptions), and the list prices of tests are often wildly inflated and/or kept secret. Therefore, while it is isn’t even clear what cost should be shown to ordering physicians, the truth of the matter is that the most overutilised routine laboratory tests do not have high unit costs, as the variable cost for additional reagents needed to run a test on a large automated platform are miniscule compared to the difficult-to-assess fixed costs of maintaining that instrument and staffing required to run it. What we might want to show physicians at the time of order would be the potential downstream costs associated with following up unnecessary testing or the potential harm that could arise to their patients, but those costs and harms are difficult or impossible to tabulate.
Another financially-based tool that has been proposed is to simply pay physicians to stop ordering laboratory testing. This is a difficult tool to administer or evaluate ethically, but it has been done using trainees. In this study (39), medical residents were paid in “book money” on a scale commensurate with the size of their collective percentage reductions in laboratory and radiology test ordering. Notably, residents were not individually rewarded for their individual performance, but rather for the performance of a group. There were overall modest reductions in test ordering through this intervention, but they were comparable to the control group, and they rebounded to pre-intervention levels after the study ceased. Residents who participated in simple chart reviews to study their own utilization patterns in this study had more significant and longer-lasting reductions in test utilization.
Whether or not tools based on provision of financial information or cash bonuses can be considered effective is perhaps not as important as the fact that third party payers or health care systems are already implementing interventions based on financial incentives (mostly negative incentives), and they will continue to implement more such incentives. While early targets are likely to be areas where the motivations for overutilization are primarily financially driven, i.e. fee-for-service reimbursement of tests with negligible or no clinical utility, US insurers are already starting to write medical policies that incorporate test utilization principles (40).
Using the toolbox
While banning tests entirely or codifying a laboratory test formulary are listed in the toolbox as the strongest interventions, it must be restated that the most successful interventions in laboratory test utilization management are those that combine various tools. One can hardly expect an intervention that bans a physician’s favourite test to succeed without an educational component aimed at explaining to that physician why the test is no longer available. The same goes for computerized order entry changes. While these changes seem the least disruptive, i.e. a single check box might disappear, the interconnectedness of health information systems is such that small changes to a laboratory’s ordering interface can have unexpected and profound downstream changes. A computerized order entry-based intervention targeted at reducing serum magnesium testing was found to paradoxically increase magnesium testing, for example, by inadvertently encouraging physicians to order serum magnesium together with serum calcium and phosphorus (41). The paradoxical effect found in this study was observed through constant utilization monitoring, allowing the investigators to institute a new, successful intervention, highlighting the fact that monitoring is a necessary part of all utilization management tools. Without ongoing monitoring of utilization, it is impossible to assess the effectiveness of any utilization management intervention. As was indicated in Rule 3 above, test utilization should be monitored on a timescale similar to how fast it is expected to change; it is not enough to measure utilization at the end of a project or the end of the year.
A final critical factor required for using the utilization toolbox is the development of a rapport between the laboratory and the rest of the hospital. Clinicians who order tests are rightfully wary of mysterious and draconian utilization management interventions forced upon them by unknown entities. Making things worse, in this author’s experience, clinicians are often surprised to learn that there are doctoral-level scientists and clinicians employed by the laboratory who are concerned with optimal utilization of laboratory tests. As education is a key tool in the toolbox, we in the laboratory must therefore embrace our roles as educators to ensure that the ideas we have are understood and appreciated by clinicians and patients alike. When done appropriately, utilization management interventions can lead to improved morale not just amongst laboratory staff, but amongst all parties involved in the process. Without all three entities (laboratory, clinician, patient) having adequate information and interest in participation, optimal utilization of laboratory testing cannot be achieved.